Is it possible to predict the success of a recipe based on its ingredients?
Is it possible to predict the success of a recipe based on its ingredients independently? The answer is no. Heston Blumenthal, the father of food pairing, needs at least 2 combined ingredients to make a special meal, however, it was possible to get good insights from the analysis.
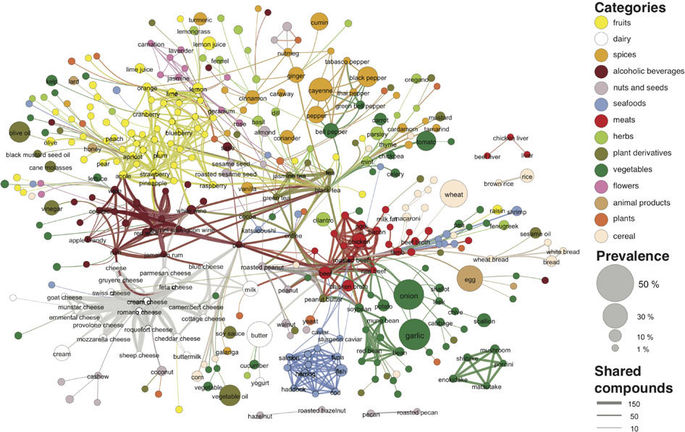
The backbone of the flavor network. Each node denotes an ingredient, the node color indicates food category, and node size reflects the ingredient prevalence in recipes. Source: Yong-Yeol Ahn, Sebastian Ahnert, James P. Bagrow, and A.-L. Barabási. “Flavor network and the principles of food pairing”(2011)
Project 2 was an opportunity for us to learn web scraping using BeautifulSoup and Selenium and Supervised Machine Learning techniques. My project was about predicting the success of a recipe based on the main ingredients and nutrition information. As a fan of the good food, I have always been curious on which elements make the dishes better. For this purpose, I chose to use a multivariable linear regression model on Epicurious.com recipes.
Data Scraping
I used BeautifulSoup for this task. Epicurious.com has an organized html source code structure, so it was not a big challenge. I automatized the search for recipes (filtered by lunch and dinner meals) and scrapping. Since it involved parsing hundreds of results pages and thousands of recipes, I made the scrapping stage in 8 batches, so I could avoid the risk of loosing information.
Feature Selection
For the target variable, I chose to measure the Success score by the rating combined with the percentage of people that said that would make that recipe again.

It seems more realistic than using purely ratings and has a better distribution.
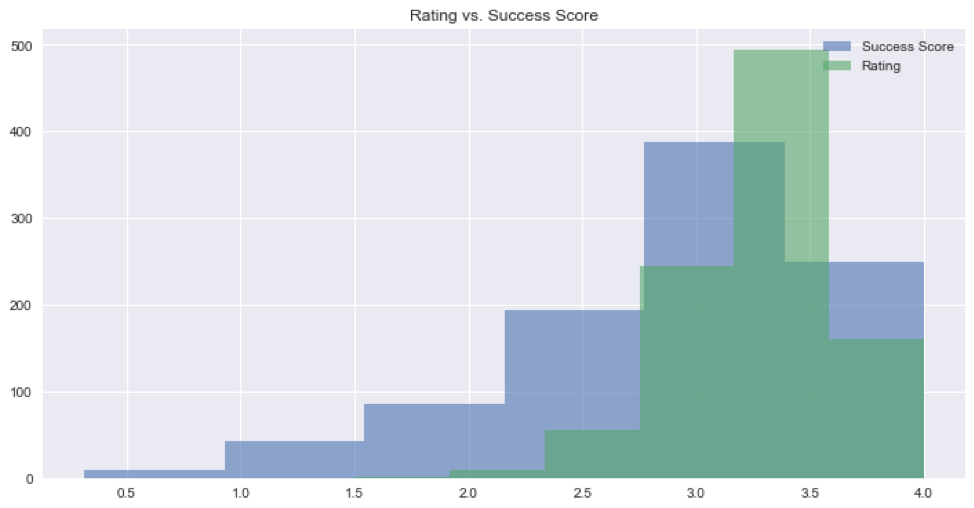
As features, 2 types of information were used:
- Nutrition data: calories, carbohydrates, sodium, protein, etc per serving
- Key ingredients: + 300 categorical features
As the nutrition data is right skewed (as in the example below), I transformed them to log, so they had a better distribution.
![]()
For the ingredients, since there were many, I used the Recursive Feature Elimination (RFE) for choosing the 50 most important ingredients that explain the ratings. The RFE ranks the predictors based on their contribution to the model.
Exploratory Data analysis
In this stage, I realized that a linear regression was not the most appropriate model for analyzing ingredients of a recipe. This method assumes that features are independent, however, the success of a recipe is a result of the combination of flavors. The interaction between ingredients should be taken into consideration.
In whatever way, the linear regression model performed well and it was possible to get some insights from its results. I used train/test split method from sklearn to divide the data in 70% train and 30% test.
When modelling with all of my features my model came out with an r-squared of 0.94 and a mean squared error of 0.59, which was better than expected. In an attempt to reduce the mean squared error, I excluded the features whose p-value were higher than 0.05 (relationship between that feature and the rating is not statistically significant). Below is the summary of the resulting OLS model.
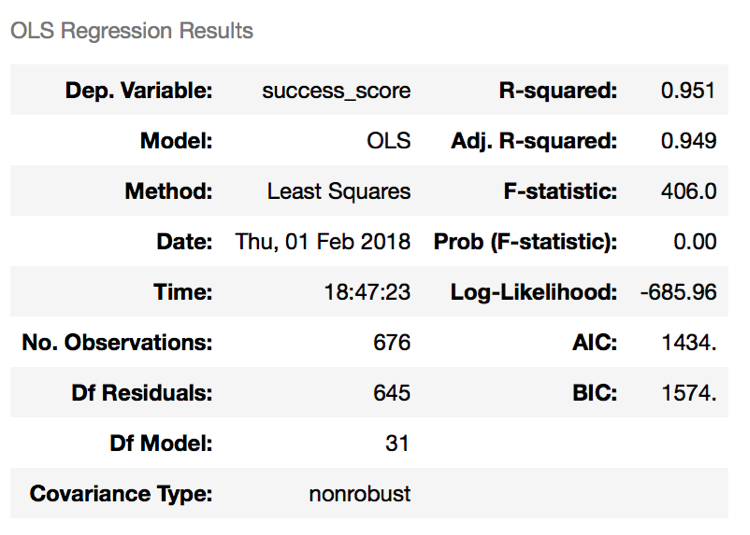
The r-squared increased to 0.95, meaning my model could account for 95% variance in the score, and a mean squared error of 0.57!
Results
- People (at least the Epicurious.com users) prefer more caloric and salty meal It resulted that unhealthier, such as calories, components have a positive coefficient,meaning that they lead to higher ratings.
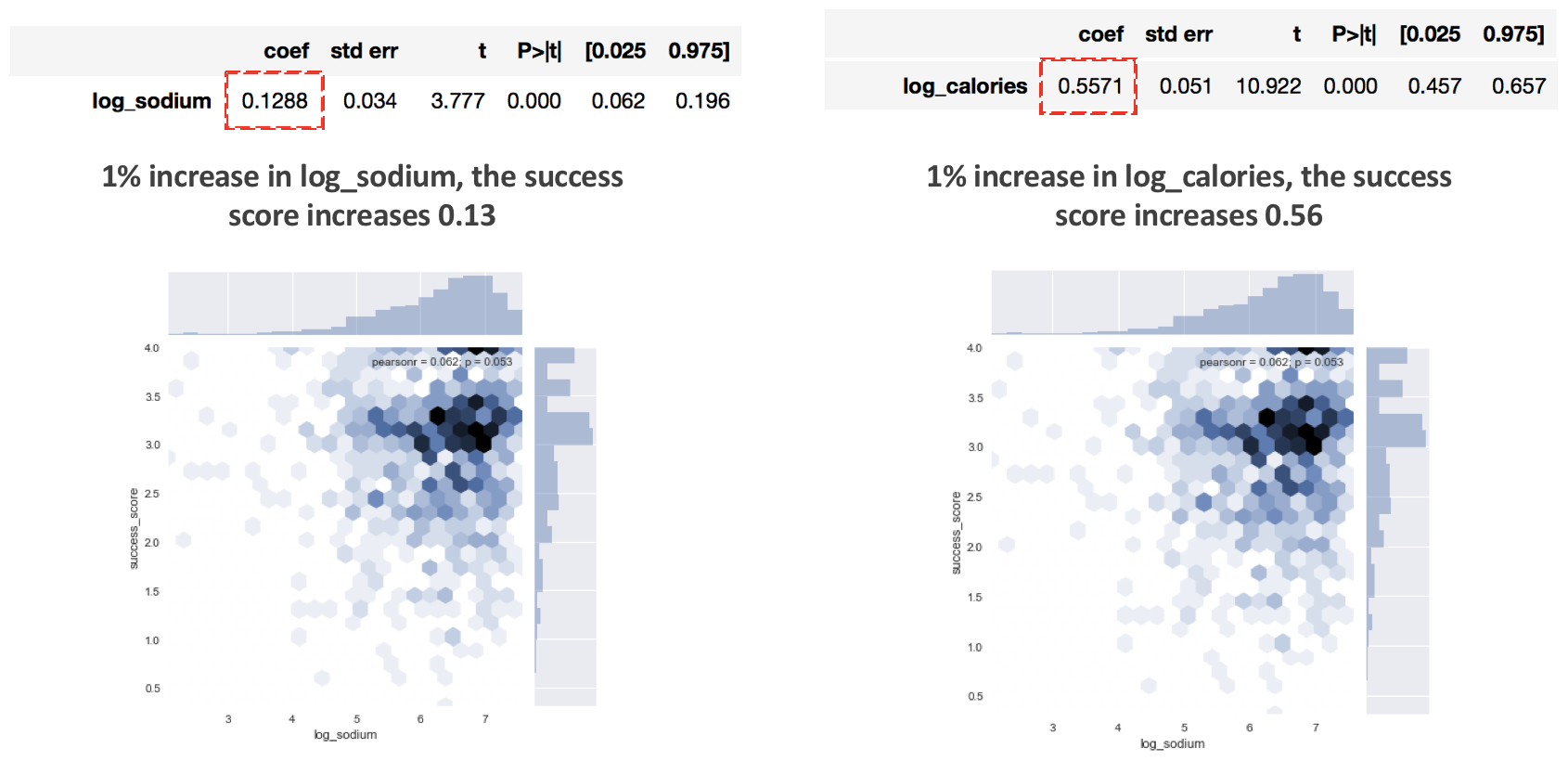
- “Fancy” ingredients may increase (or decrease) the rating
If you look closer to the ingredients that most impact the ratings, you come to the conclusion that they are mostly not main ingredients, but flavor additions to the recipes!

These ingredients are usually the ones that people love or hate, for example, pinapple. Most people I know dislike pinapple in their meal, in fact it had an negative correlation with the success score.
Next Steps
I had fun working on this project! I plan to improve it by using a classification method instead, preferably Random Forests to capture the combination of ingredients, and combine with the sentiment analysis of the reviews.