Predicting what user reviews are about with Topic Modeling and Sentiment Analysis
A few years ago, I was searching for a skin treatment and found this website called Realself. It’s the best source of information for those who are planning to do some aesthetic procedure, where thousands of users share their experience on treatments, like writing a diary.
After reading many reviews, I found four different treatments that offered similar outcomes based in the before and after pictures and chose the one that required less sessions to achieve the desired result. It was the most expensive one and with longer downtime, however, provided faster results.
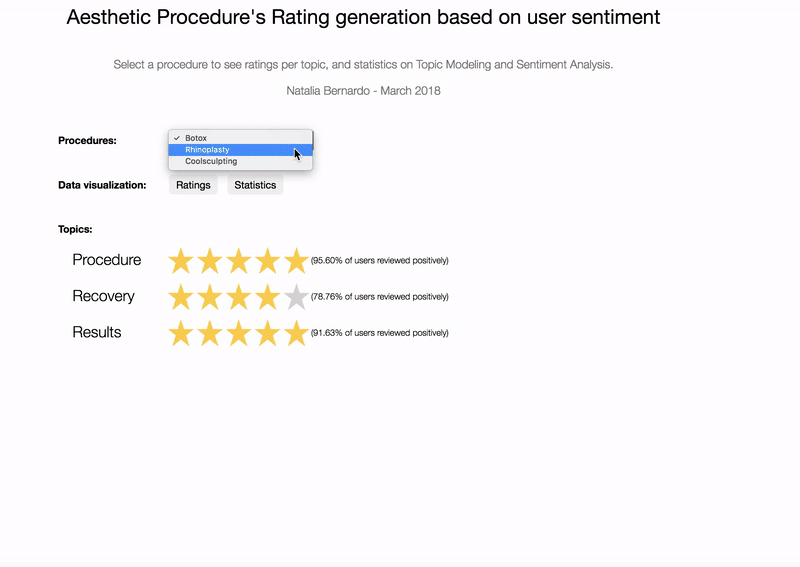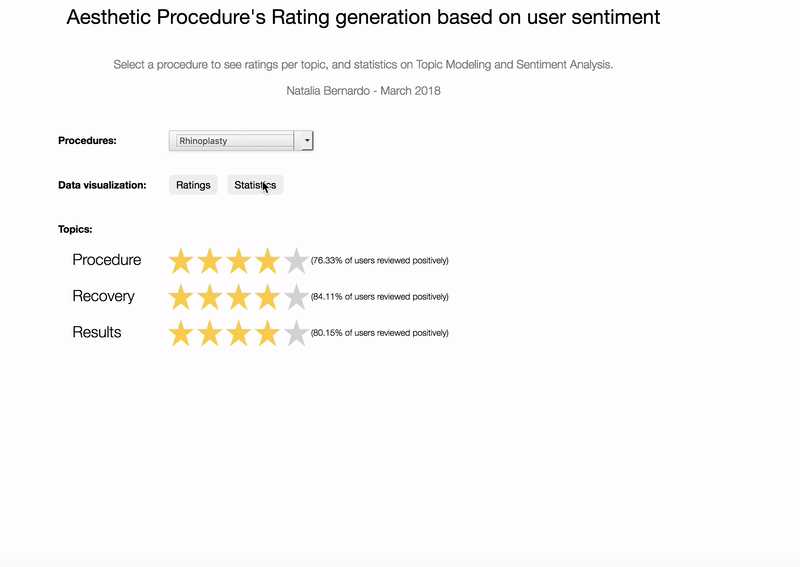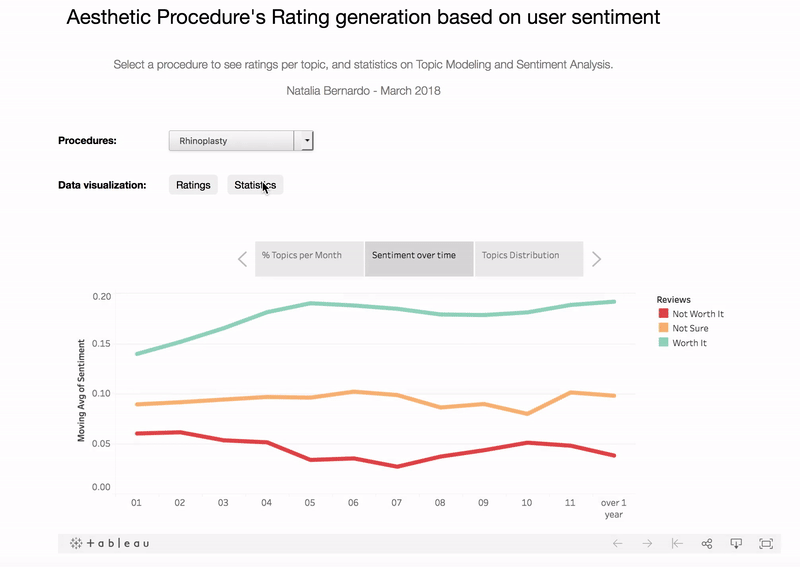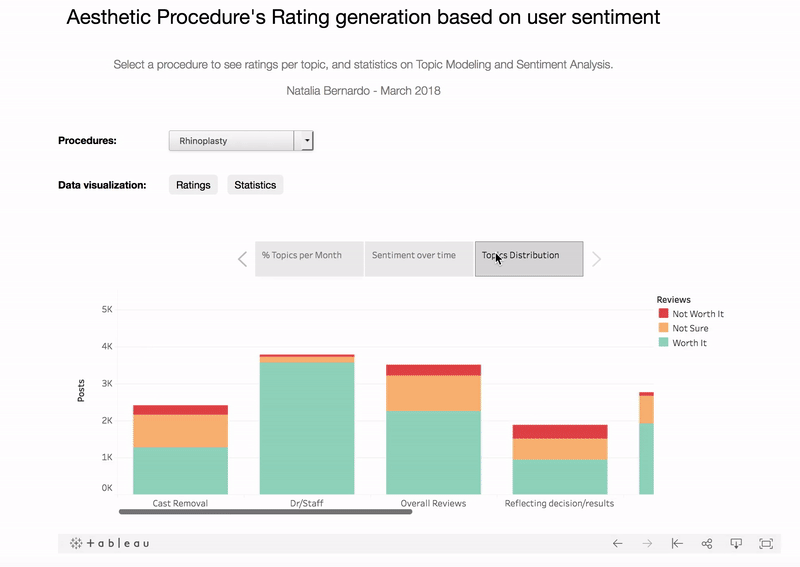
There are two different types of reviews in Realself: (1) for doctors and (2) for procedures. Pacients review doctors for 9 different categories and procedures for 1 category (“worth it”, “not worth it” or “not sure”), as you can see in the image below.
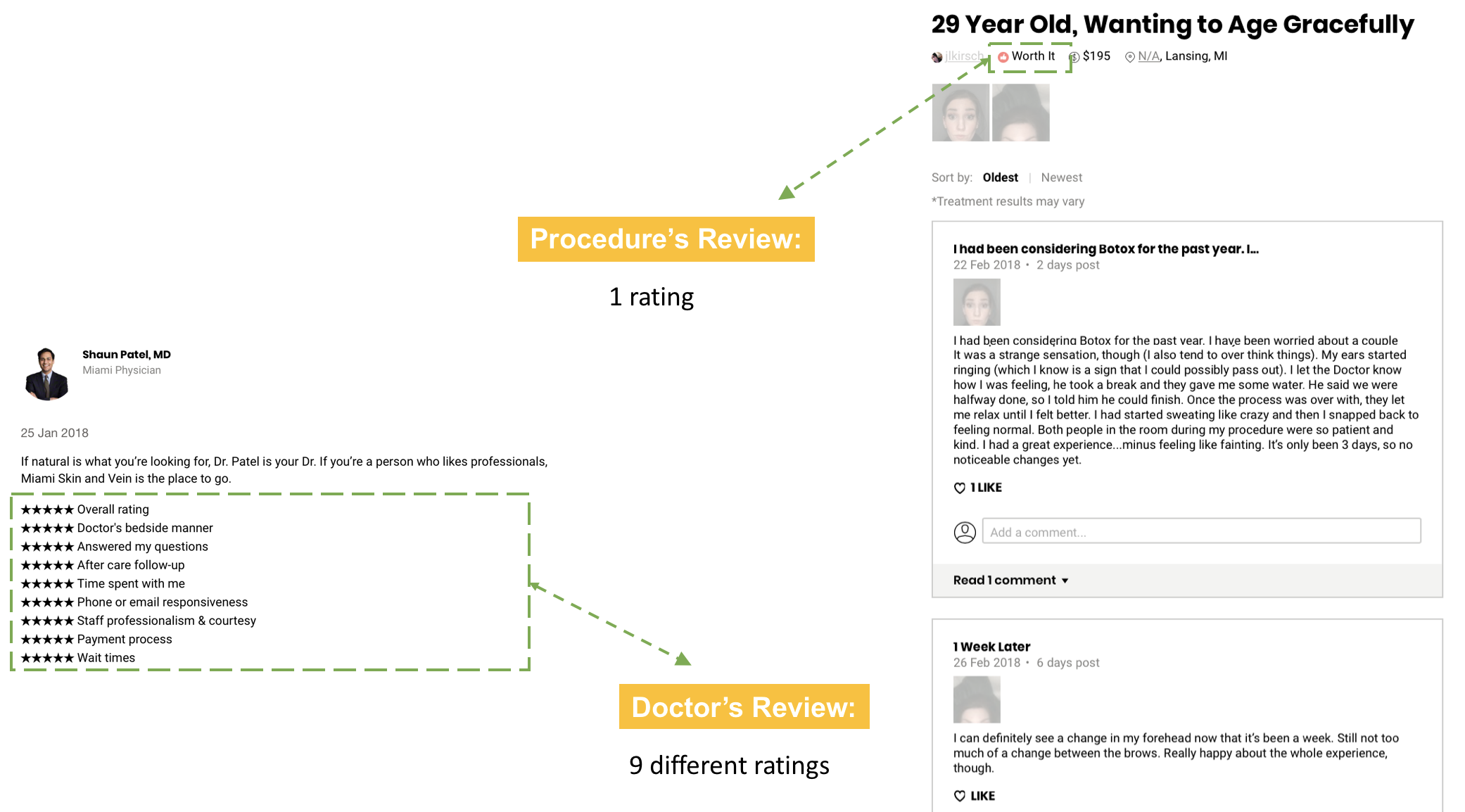
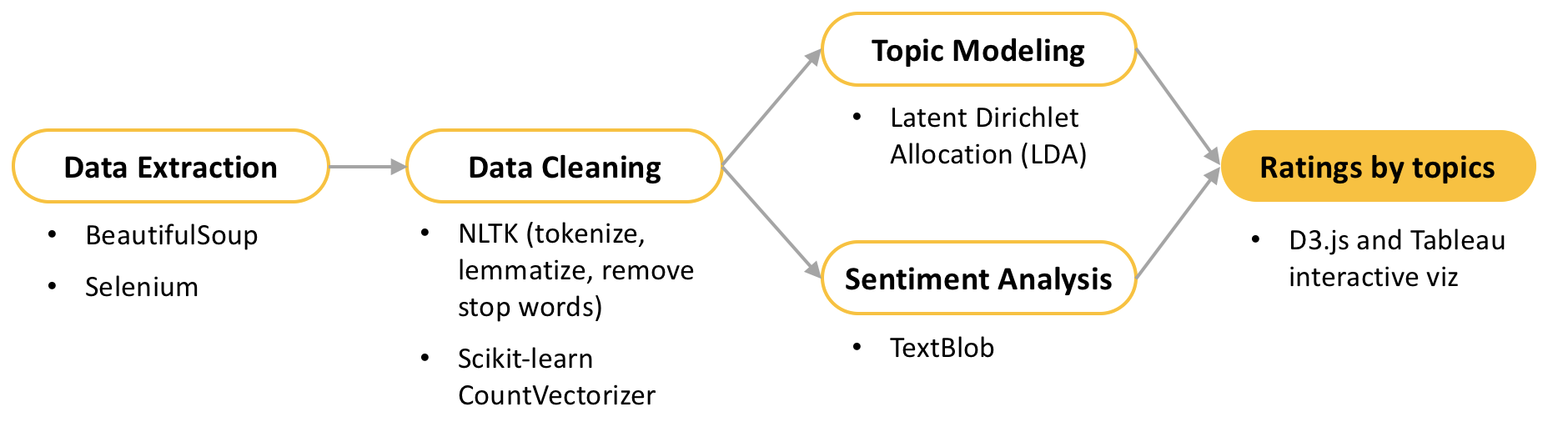
So I thought it would be interesting to uncover what customers talk more about in those long posts. For this task, I used a topic modelling method called Latent Dirichlet Allocation (LDA), a Natural Language Processing (NLP) tool that can automatically identify topics from a corpus. A “topic” consists of a group of words with some semantic relation that frequently occur together.
Having the topics defined, I decided to predict how the users would rate their experience on those themes, in other words, I simulated the ratings for the potential subcategories of the procedures (such as for the doctors’ reviews) based on user’s sentiments. I used Textblob Sentiment for classifying each sentence of the posts as “negative” or “positive”.
The results were presented in an interactive viz (click here), where you can explore the ratings, topics by procedure and sentiment over time.
Feel free to check out my code on my github!
1. Data collection and cleaning
I extracted all posts (53,547 posts from 17,270 unique users) of all reviews from 3 different procedures: botox, rhinoplasty and coolsculpting. I used BeatifulSoup and Selenium for obtaining the data, and stored it in MongoDB.
Four steps are important for any natural language processing project:
- tokenize - split up the document (post) into words
- lemmatize - get each word down to its root form (i.e. walking -> walk, better -> good)
- remove stop words - the most common words in a language (i.e. the, is, at, which)
- vectorize - transform text into a vector of numbers
I used the Python’s libraries NLTK and sckit-learn’s CountVectorizer, that takes each word in each document and counts the number of times the word appears.
Using CountVectorizer, I built a word matrix choosing a max_df of 80% and min_df of 10, meaning that the matrix would exclude words that appeared in more than 80% of the texts (to avoid commonly used terms) and less than 10 times. I also chose an ngram range of (1, 3) - pairs or triplets of words that show up together - to be able to capture terms of two or three words commonly used together.
2. LDA to identify “hidden” topics in reviews
I experiemented with different topic modelling techniques: LDA, non-negative matrix factorization (NMF) and k-means, and LDA’s topics were easier to interpret. In this model, each topic from a corpus of text documents is defined as a multinomial distribution over a word dictionary with words drawn from a dirichlet distribution.
However, it’s not always an easy task. It requires human judgments to assign a category to the topic by looking at the words in it, so it has some subjectivity. Some example of topics identification for Rhynoplasty:
Surgery/pos op: day, feel, pain, take, sleep, surgery, night, really, wake, good, eye, bad, hour, today, help, much, time, make, start, also, bruise, come, lot, eat, mouth, well, around, keep, home, thing, nurse, think, back, bit, breathe, blood, swell, last, recovery, morning, first, say, use, put, dry, try, pretty, could, cast, able
Doctor/staff: dr, surgery, result, look, good, feel, make, happy, want, surgeon, staff, recommend, great, doctor, year, amazing, natural, experience, always, time, comfortable, know, could, plastic, love, work, make feel, care, decision, extremely, even, consultation, take, recovery, well, highly, one, thank, exactly, process, feel comfortable, confident, patient, choose, see, first, question, happy result, meet, decide
Discomfort (and first impressions): look, swell, day, feel, cast, see, week, good, really, tip, much, swollen, swelling, take, happy, today, think, bit, say, come, love, back, time, even, remove, new, stitch, normal, know, wait, lot, pic, nostril, notice, tape, result, side, one, since, right, pretty, also, eye, well, smile, change, skin, splint, removal, bruise
After carefully examining the results, I visually labeled the topics and, as expected, they were peculiar for each treatment:

I realized that despite having different themes, the reviews could be divided into 3 big topics: Procedure, Recovery and Results.
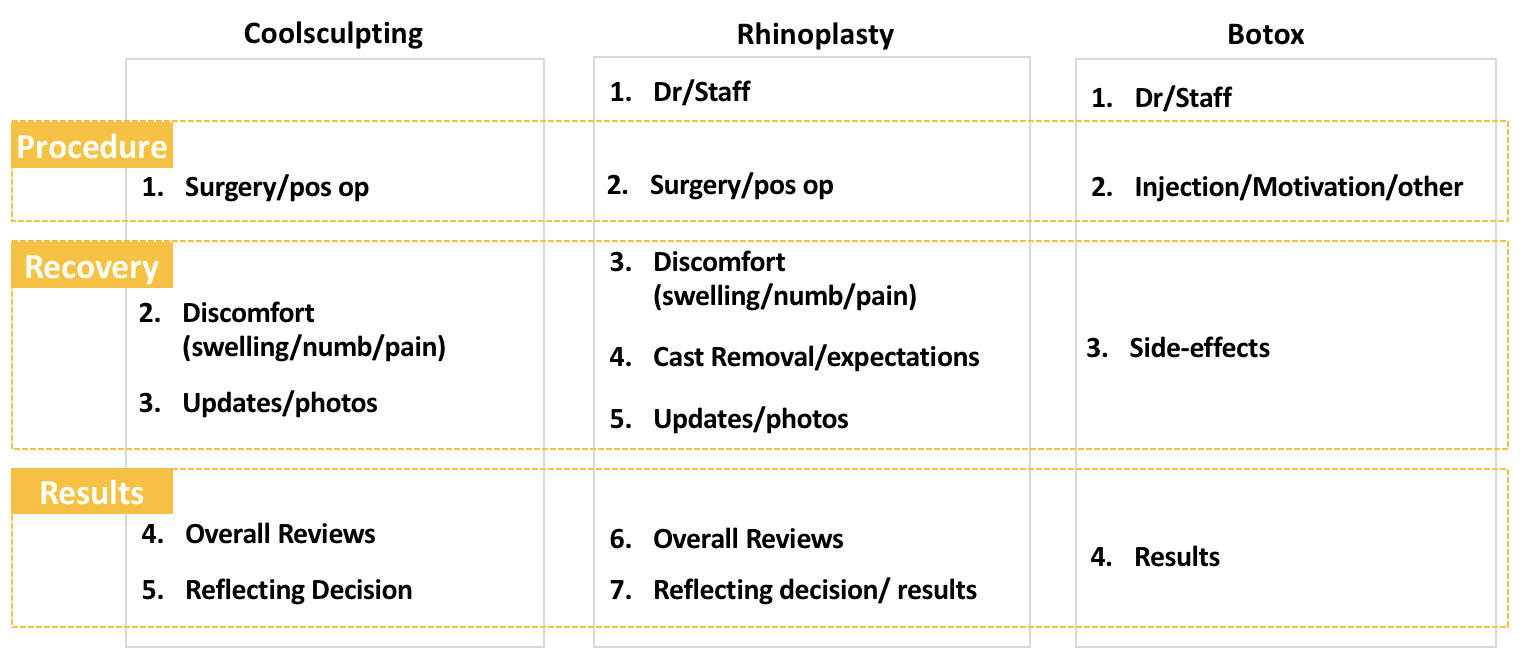
The next step was to assign ratings for each one of those aggregated topics.
3. Sentiment Analysis to assign ratings for topics
One possible approach to define the rating for the topic is to compute the percent of positive comments in each treatment, similar to the Rotten Tomatoes scores. For this task I tried both Vader and TextBlob, and the later provided better results: the “not worth it” reviews had more negative comments, while the “worth it” reviews had more positive comments.
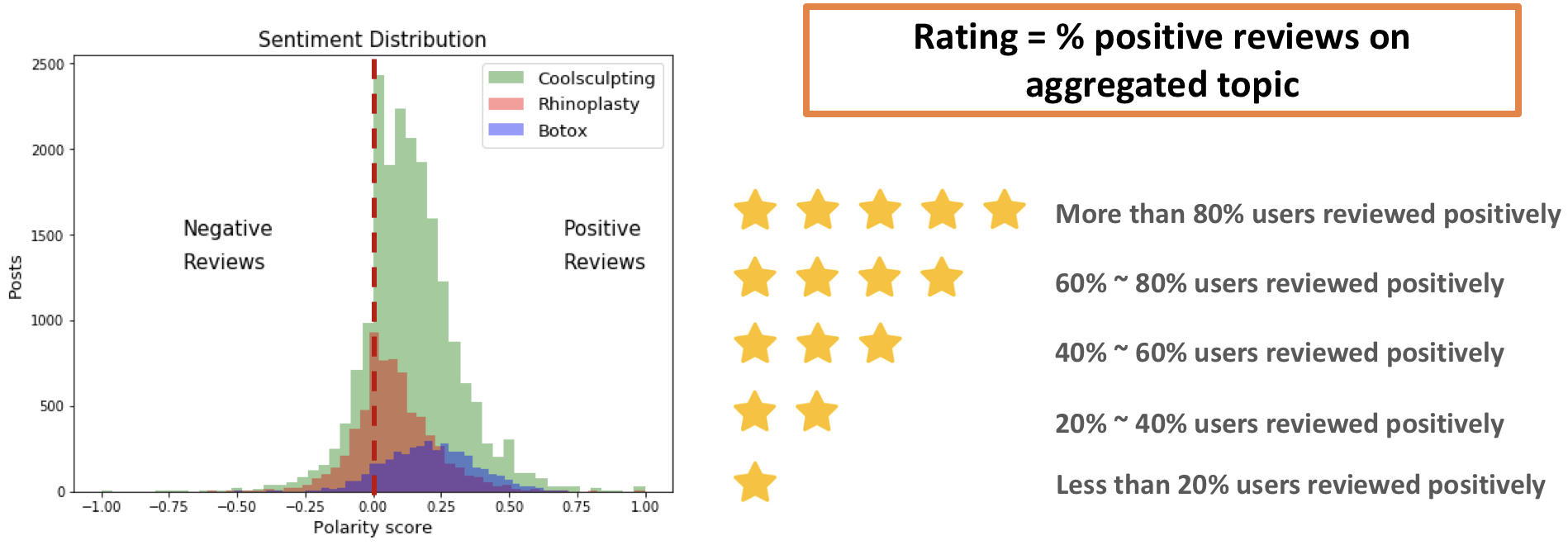
As expected, the more invasive procedures that render more drastic results, the more negative sentiment its posts receive. It’s because patients are more expositive on concerns with the aesthetic results. For example, although ryhoplasty is given a high “worth it” rate (90%), many patients face anxiety during the recovery period, since they cannot see the final results immediately and have to wait some time until the swollen is gone. On the other hand, minimally or non-invasive treatments like coolsculpting and botox tend to receive more positive sentiment reviews (curiously, the majority of negative sentiment reviews to coolsculpting are related to the minimal results of the procedure).
Demo
(Click here) to view it in full screen.
Conclusions & Future work
Online reviews are a big factor in a company’s reputation, however it’s challenging to oversee all the opinions posted on review platforms. For minimizing the workload, I experimented applying machine learning and text mining methods to identify relevant themes present in those opinions, using semantic topic modeling.
In fact, probabilistic topic models are becoming popular tools to uncover what other users think about a product. On the service provider’s side, it can give good insights of what users most care about when purchasing a product or a service. On the user’s side, it allows the provider to personalize the content of the reviews platform in order to shorten the time an user needs to make a decision, for example, creating rating for specific categories.
As next steps, I would like to expand the project developing:
Improve Topic Modeling
I had only 2 weeks to complete this project, so it still has room for improvement. With more time, I would like to test more scenarios and tweak the parameters in order to increase the accuracy of the model. And also, extend the analysis for more procedures.
Classification model (SVM) for assigning topics to new reviews.
When a new document (review) is added to the corpus, we don’t need to redo all the work. Once we build a suport vector machine (SVM) classifier, it’s possible to quickly predict the topic of this new review.
Comparison tool
There’s a trade-off between downtime and results: while some people prefer shorter recovery time, others prefer drastic results. So if patients had a tool to compare between treatments with similar goals (e.g. liposuction vs. Coolsculpting) based on their priorities, they could spend less time in their research and choose the most appropriate procedure for their expectations, and avoid frustating experiences like:

Extract Reviews’ Highlights
Additionally, It’s possible to improve the user’s search experience by adding highlights from reviews. To choose the most relevant sentences, we could make use of the social engagement tools that Realself provides, such as comments and likes, as well as sentiment and term frequency.