Using Convolutional Neural Network to identify curb ramps on images
Identifying Curb Ramps on Sidewalks through Google Street View images
When I moved to Seattle, one year ago, I noticed that some neighborhoods were not served with disabled-friendly sidewalks, especially because not every corner had a curb ramp. Fortunately, the City is making an effort for adding ADA (Americans with Disabilities Act) compliant curb ramps on its streets.
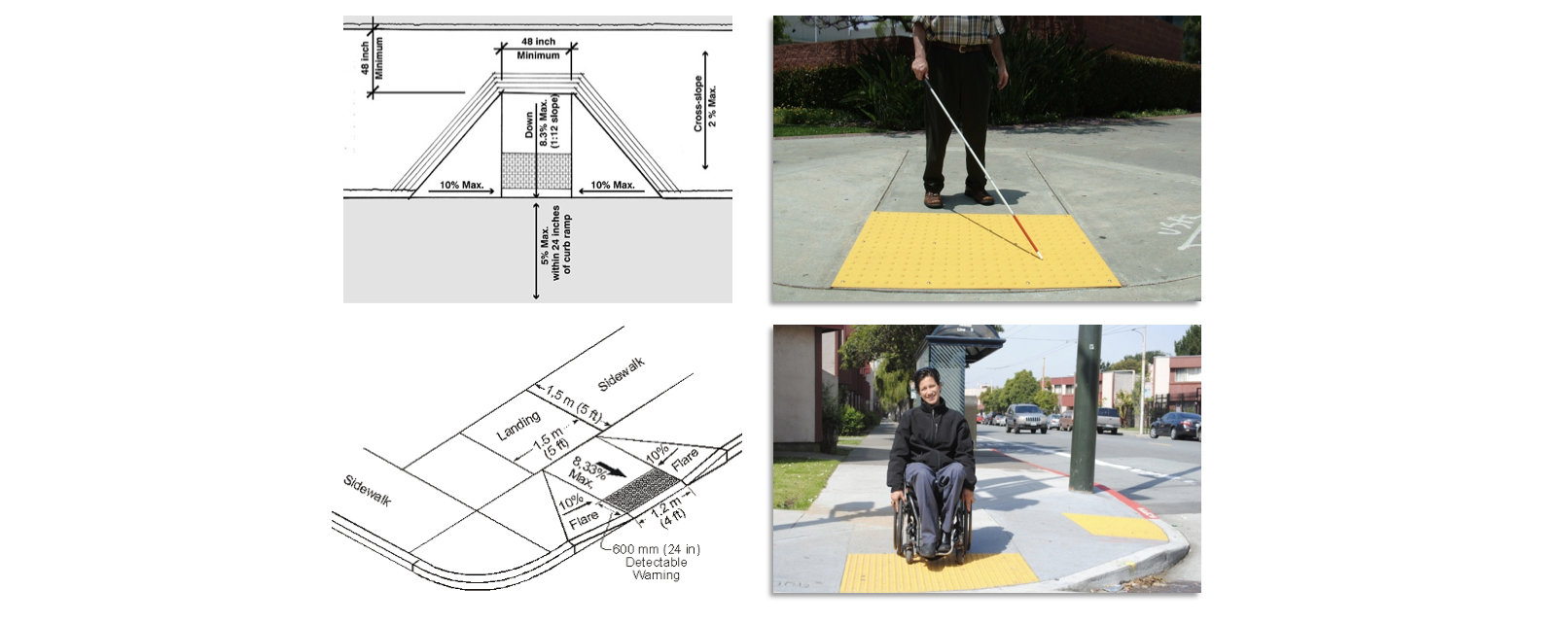
The Seattle Department of Transportation (SDOT) just started implementing a Pedestrian Master Plan, that required a minutious assessment of curb ramp’s condition. However, this work is costly usually being executed through mapathons. And not all cities have enough resources to do it.
For this reason, the goal of my project is to try to automatize this task and make it accessible to other cities, by recognizing the curb ramps directly from Google Street View’s images, with a convolutional neural network classifier. More specifically, using Tensorflow Object Detection.
As a pilot project, I mapped the curb ramps in Fremont. I chose this neighborhood because it’s very welcoming for pedestrians, with street festivals, touristic spots and with many tech companies located there.
1. Extracting images from Google Street View
The images used for this project were the pictures of intersections, extracted from the Google Street View API. Fortunately, a University of Washington’s project named AccessMap, which was designed to improve the sidewalk data for pedestrians, already provided the coordinates of all intersections in Seattle using SDOT’s data.
After that, I manually labelled 1500 images, drawing rectangles around the curb ramps for teaching the model which object I’m trying to recognize (I will explain the labelling process later).

2. Choosing the Model
Method for identifying curb ramps on images
There are different ways of identifying a specific class on images, as illustrated in the picture below.
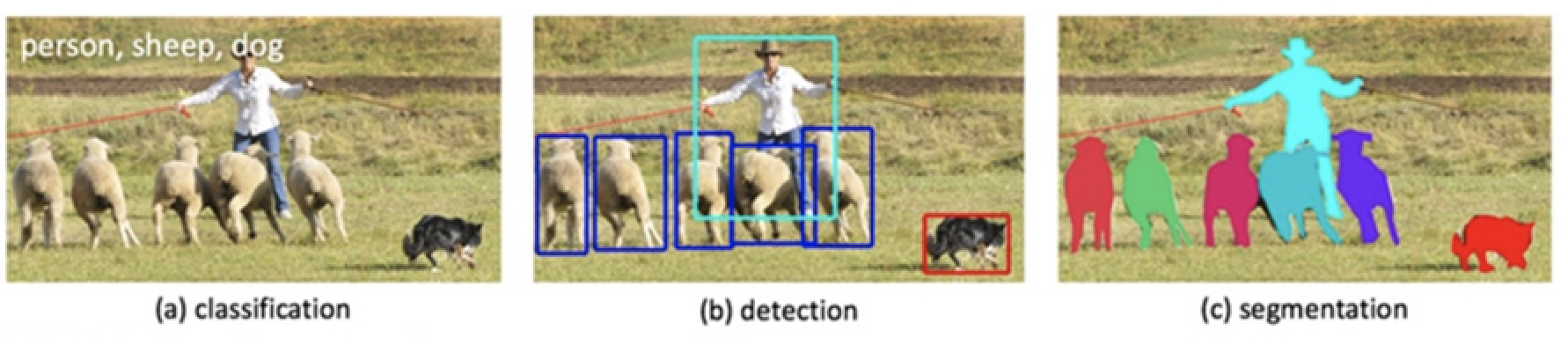
Source: Facebook Research
For this project, I chose to use the “object detection” method. Since I’m training the model with images for custom object classes, “object detection” would only require me to draw simple bounding boxes around the ramps instead of the complex polygons that “object segmentation” would need. And I believe that it would be an even trickier task to use the “image classification” method for this category without any visual cue of the multiple curb ramps identified on a photo.
As a headstart on my quest, using the Tensorflow Object Detection API - released by Google in 2017 – greatly facilitated this task.
Tensorflow Object Detection API:
The Object Detection API allows us to use models trained on Microsoft COCO dataset (a dataset of about 300,000 images of 90 commonly found objects), and fine-tune then with a custom data set to detect new classes (process called transfer learning). It also includes image augmentation features, such as flipping and saturation adjustments.
Transfer Learning Architecture
With the transfer learning process, it’s possible to shorten the amount of time needed to train the entire model. A typical object detection model requires thousands of images and some weeks of training, but, fortunately, we can take advantage of an existing pre-trained model and just retrain its final layer(s) to detect curb ramps for us. Tensorflow does offer a few good pre-trained models to start (in the tensorflow model zoo).
There’s a speed/accuracy trade-off when choosing the object detection model, as depicted in the image below:
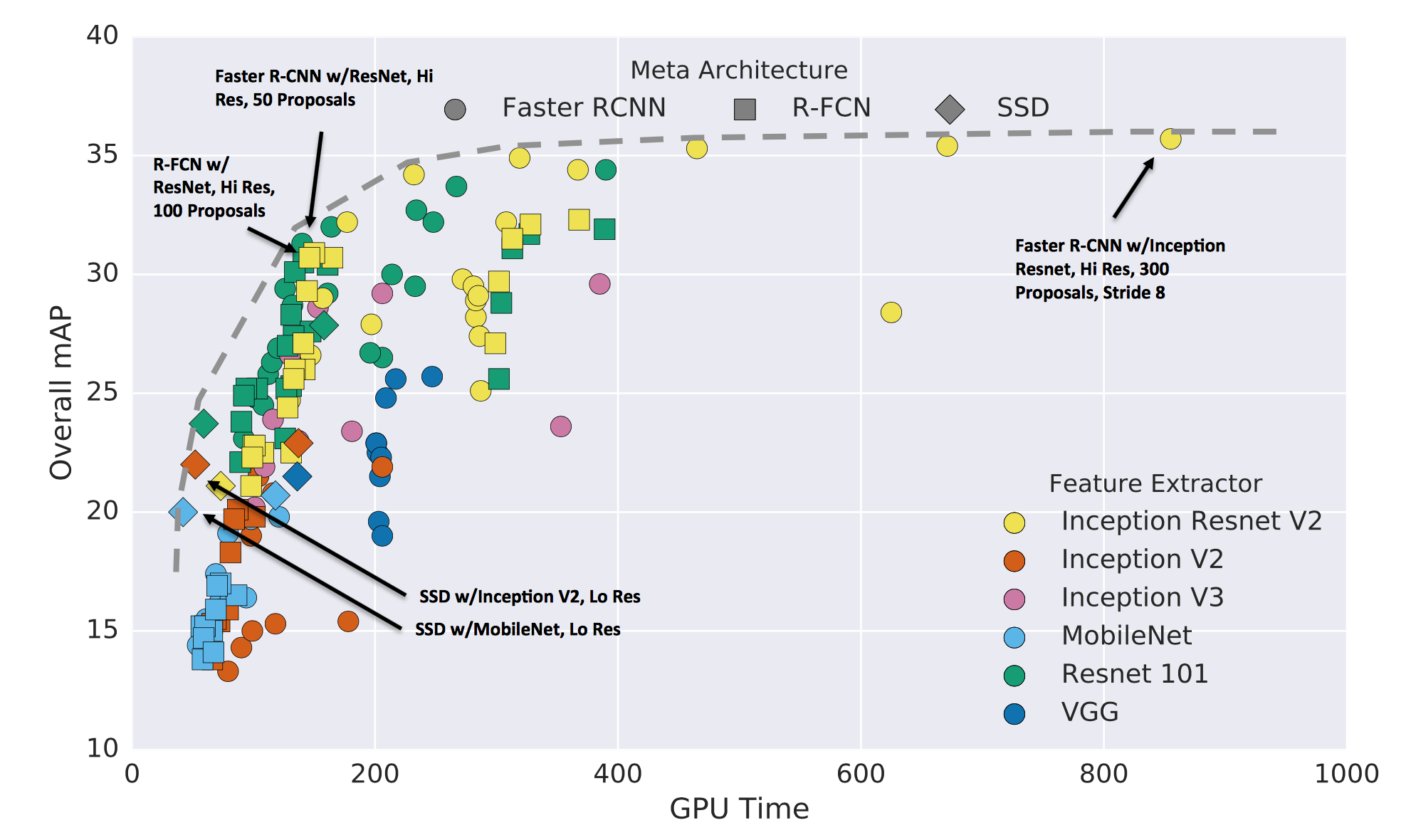
Source: Speed/accuracy trade-offs for modern convolutional object detectors
For finding the best pre-trained model for object detection. I tried different arrangements and the one that provided more accurate results at a better speed was the Faster R-CNN, which is a region based convolutional network, using ResNet feature extractor.
In fact, the sweet spot is the “elbow” part of the mAP (Mean Average Precision) vs GPU time graph, exactly where the Faster R-CNN with ResNet is located.
![]()
3. Preparing the Data
Labelling the images
First, I filtered the streets’ intersections images that were classified by SDOT as having curb ramps. Afterwards, I draw rectangles around curb ramps in 1500 images using VOTT. I found this labelling tool more user-friendly than Rectlabel.
I decided to distinguish ramps between likely ADA compliant and non-ADA compliant. For this reason, I created 2 classes:
- Yellow: likely ADA compliant curb ramp (with a yellow tactile warning)
- Grey: likely non-ADA compliant curb ramp (without or grey tactile warning)
Convert data to TFRecord format
Tensorflow Object Detection API uses the TFRecord file format, so at the end we need to convert our dataset to this file format. I generated a tfrecord using a code adapted from this raccoon detector .
4. Training the Model
Once I decided the architecture, the first step for training, was to download the Faster-RCNN_ResNet model.
wget http://download.tensorflow.org/models/object_detection/faster_rcnn_resnet50_coco_2018_01_28.tar.gz
tar xvzf faster_rcnn_resnet50_coco_2018_01_28.tar.gz
For installing the Object Detection API, you need to run the following code on the root directory:
git clone https://github.com/tensorflow/models.git
cd models/research/
protoc object_detection/protos/*.proto --python_out=.
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
cd ..
cd ..
Finally, I could train the model, using the command:
python3 models/research/object_detection/train.py \
--logtostderr \
--train_dir=${PATH_TO_TRAIN_DIR} \
--pipeline_config_path=${PATH_TO_YOUR_PIPELINE_CONFIG}
I used tensorflow-gpu 1.5 on a Win10 machine with a NVIDIA GeForce GTX 970 4GB, following the installation steps described on the Tensorflow website. By using a GPU, the training was 10+ times faster than using tensorflow without GPU support.
I splitted the images dataset into approximately 80% / 20% train/test ratio. Once training was complete, it was time to test the model. The following command export the inference graph based on the best checkpoint:
python3 models/research/object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path ${PIPELINE_CONFIG_PATH} \
--trained_checkpoint_prefix ${TRAIN_PATH} \
--output_directory object_detection_graph
Finally, I applied the trained model to the Google Street View images of Fremont’s corners.
5. Results!
I was happy with the results so far. The predictions using Faster R-CNN ResNet were significantly more accurate than in my previous attempt (using SSD MobileNet).

With 75% recall (the % of ramps that could be detected) and 80% precision (the % of correctly detected ramps), the model identified curb ramps and classified them as likely to be ADA compliant or not compliant. The majority of wrong predictions are false negatives, usually because the ramp is not entirely on the picture, or it is too distant, or covered by shadow.
Finally, I plotted the results on a map. The markers indicate where there are curb ramps, with the green ones indicating where they are likely to be ADA compliant, and the yellow ones indicating where they are likely to be non-ADA compliant.
Bonus: I also tested the model using MoviePy’s VideoFileClip in a short video that I recorded at Pioneer Square in Seattle. VideoFileClip applies the classification on each frame of the video, and you can see the curb ramps being identified in real time on the video below:

6. Conclusions & Next Steps
I decided to do this project because I wanted to find a cheaper and faster way to assess to curb ramps’ condition within a city. And it proved that it is possible to detect them, identify if they are ADA compliant, and automatize this process. There’s still room for improvement. However, for those cities that don’t have resources, it’s a good start.
As next steps, I plan to:
- Adjust the image augmentation to improve the precision.
- Improve the algorithm for extracting images of corners from Google Street View, to make sure that the ramp is entirely on the image.
- Expand to Seattle, beyond Fremont.